说明
来着姜胡说小马哥
操作步骤
- 使用浏览器打开小红书和抖音
- 进入到作品详情页
- 按下 F12 键,打开开发者模式
- 在 console 执行对应代码(代码在最下方,先看完文档)
-
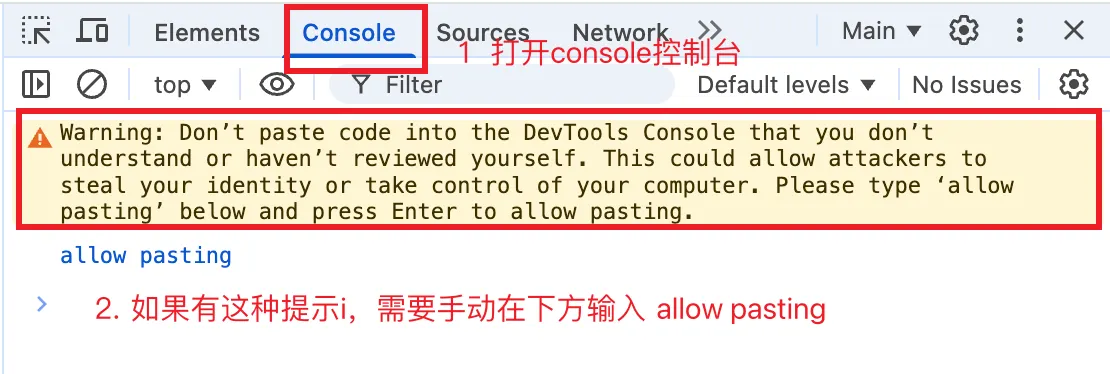
第一次使用,需要输入 allow pasting 指令,允许在 console 进行粘贴
-
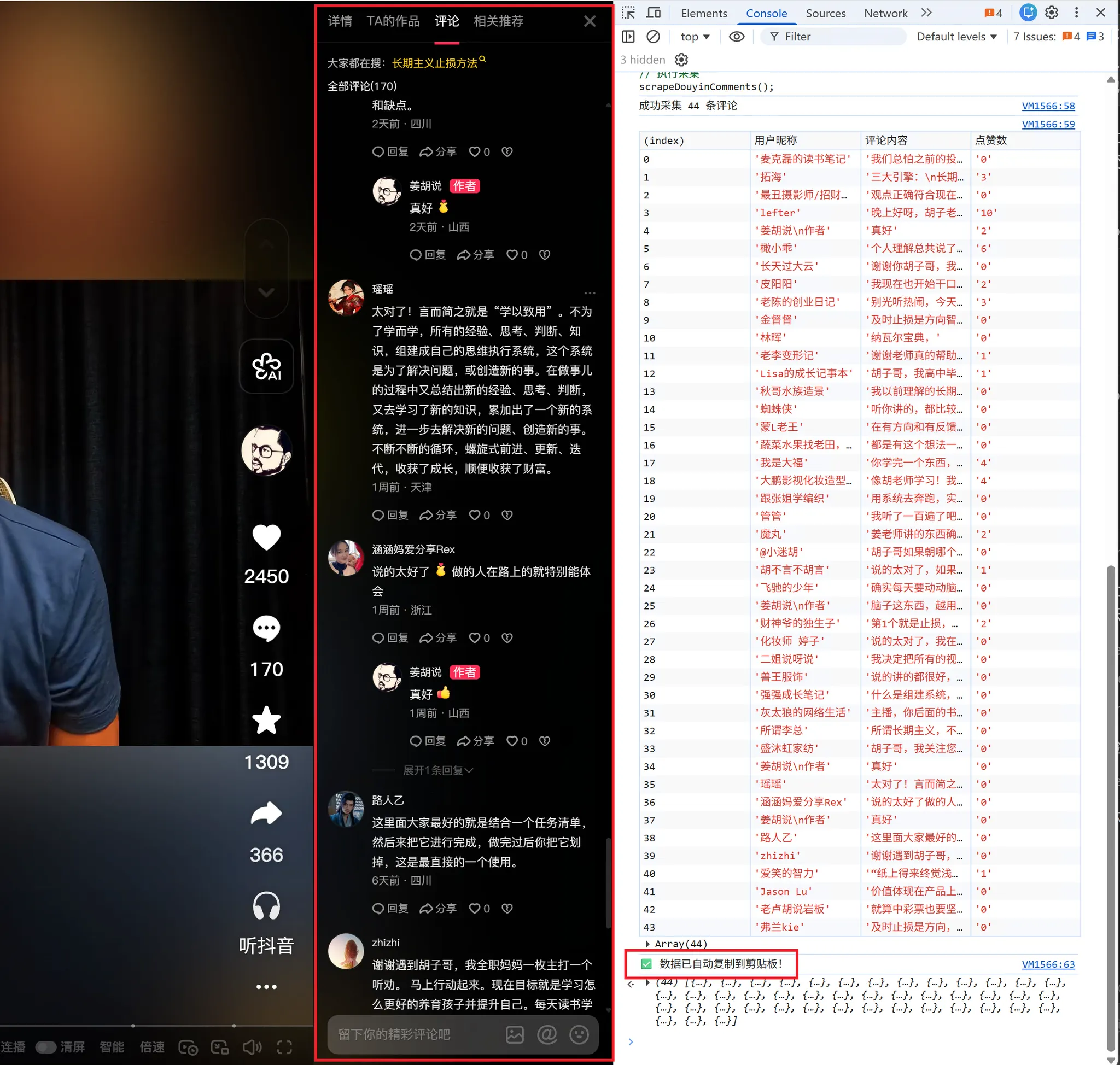
打开评论区,往下手动滚动评论区内容,滚动越长,可以采集到的评论就越多
-
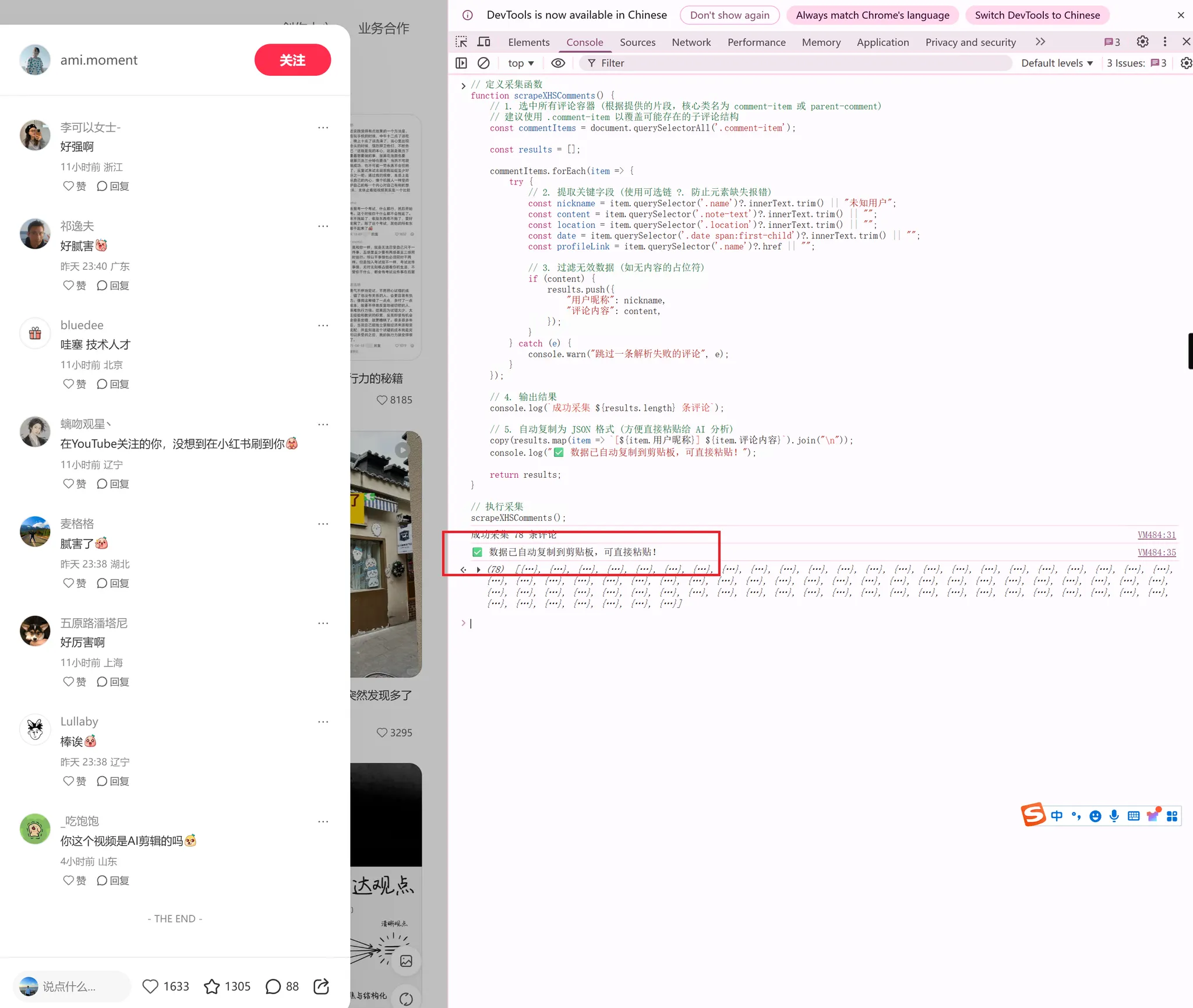
然后把对应代码粘贴到 console,按回车键执行,评论就自动复制到剪切板了
-
1. 小红书评论区采集脚本
-
复制以下代码,到浏览器 console 执行
// 定义采集函数 function scrapeXHSComments() { // 1. 选中所有评论容器 (根据提供的片段,核心类名为 comment-item 或 parent-comment) // 建议使用 .comment-item 以覆盖可能存在的子评论结构 const commentItems = document.querySelectorAll('.comment-item'); const results = []; commentItems.forEach(item => { try { // 2. 提取关键字段 (使用可选链 ?. 防止元素缺失报错) const nickname = item.querySelector('.name')?.innerText.trim() || "未知用户"; const content = item.querySelector('.note-text')?.innerText.trim() || ""; const location = item.querySelector('.location')?.innerText.trim() || ""; const date = item.querySelector('.date span:first-child')?.innerText.trim() || ""; const profileLink = item.querySelector('.name')?.href || ""; // 3. 过滤无效数据 (如无内容的占位符) if (content) { results.push({ "用户昵称": nickname, "评论内容": content, }); } } catch (e) { console.warn("跳过一条解析失败的评论", e); } }); // 4. 输出结果 console.log(`成功采集 ${results.length} 条评论`); // 5. 自动复制为 JSON 格式 (方便直接粘贴给 AI 分析) copy(results.map(item => `[${item.用户昵称}] ${item.评论内容}`).join("\\n")); console.log("✅ 数据已自动复制到剪贴板,可直接粘贴!"); return results; } // 执行采集 scrapeXHSComments();
2. 抖音评论区采集脚本
- 复制以下代码,到浏览器 console 执行
// 定义抖音评论采集函数
function scrapeDouyinComments() {
// 1. 选中所有评论容器 (优先使用 data-e2e 属性,比混淆类名更稳定)
// 注意:抖音评论区是懒加载的,运行前请手动向下滚动加载更多评论
const commentItems = document.querySelectorAll('[data-e2e="comment-item"]');
const results = [];
commentItems.forEach(item => {
try {
// 2. 提取关键字段
// 昵称:通常在 comment-item-info-wrap 下的链接文本中
const nameEl = item.querySelector('.comment-item-info-wrap a');
const nickname = nameEl ? nameEl.innerText.trim() : "未知用户";
// 内容:寻找包含文本的核心 span,通常在 info-wrap 下方
// 这里尝试匹配提供的 HTML 结构中的内容容器
const contentEl = item.querySelector('.C7LroK_h span');
const content = contentEl ? contentEl.innerText.trim() : "";
// 时间与地点:通常格式为 "1年前·湖南"
const metaEl = item.querySelector('.fJhvAqos');
let date = "";
let location = "";
if (metaEl) {
const metaText = metaEl.innerText.trim();
if (metaText.includes('·')) {
const parts = metaText.split('·');
date = parts[0].trim();
location = parts[1].trim();
} else {
date = metaText; // 只有时间没有地点的情况
}
}
// 点赞数:寻找 SVG 图标旁边的数字
// 抖音的点赞通常在某个统计容器里,这里根据 HTML 找 .xZhLomAs 或类似结构
// 兜底策略:直接找 innerText 长度较短且包含数字的元素,或者根据 DOM 位置
const likeEl = item.querySelector('.comment-item-stats-container p');
const likes = likeEl ? likeEl.innerText.trim() : "0";
// 3. 过滤无效数据
if (content) {
results.push({
"用户昵称": nickname,
"评论内容": content,
"点赞数": likes
});
}
} catch (e) {
// 抖音结构非常复杂,容错处理很重要
console.warn("跳过一条解析失败的评论", e);
}
});
// 4. 输出结果
console.log(`成功采集 ${results.length} 条评论`);
console.table(results);
// 5. 复制到剪贴板
copy(JSON.stringify(results, null, 2));
console.log("✅ 数据已自动复制到剪贴板!");
return results;
}
// 执行采集
scrapeDouyinComments();